
تشخیص اشیا یکی از وظایف اصلی در حوزه Computer Vision است که فناوریهایی از خودروهای خودران تا نظارت ویدئویی در زمان واقعی را پشتیبانی میکند. این فرآیند شامل شناسایی و مکانیابی اشیا در داخل یک تصویر است و پیشرفتهای اخیر در Deep Learning این وظیفه را دقیقتر و کارآمدتر کرده است. یکی از نوآوریهای جدید که تشخیص اشیا را پیش میبرد، Vision Transformer (ViT) است؛ مدلی که با تواناییاش در ثبت زمینه جهانی (global context) بهتر از روشهای سنتی، چشمانداز پردازش تصویر را تغییر داده است.
در این مقاله، ما به بررسی جزئیات تشخیص اشیا Object Detection میپردازیم، قدرت Vision Transformers را معرفی میکنیم و سپس یک پروژه عملی را قدم به قدم پیش میبریم که در آن از ViTs برای تشخیص اشیا استفاده خواهیم کرد. برای جذابتر شدن، یک رابط تعاملی نیز ایجاد میکنیم که به کاربران اجازه میدهد تصاویر را بارگذاری کنند و نتایج تشخیص اشیا را در زمان واقعی ببینند.
آنچه خواهید آموخت:
- تشخیص اشیا Object Detection چیست و چرا اهمیت دارد.
- Vision Transformers (ViTs) چگونه با شبکههای عصبی سنتی متفاوت هستند.
- پیادهسازی گامبهگام تشخیص اشیا با استفاده از ViTs و PyTorch.
- ساخت یک ابزار تعاملی برای تشخیص اشیا با استفاده از ipywidgets.
مقدمهای بر تشخیص اشیا
تشخیص اشیا یک تکنیک Computer Vision است که برای شناسایی و مکانیابی اشیا در داخل تصویر یا ویدئو استفاده میشود. این را میتوان به آموزش یک کامپیوتر برای دیدن و تشخیص چیزهایی مثل گربهها، خودروها یا حتی افراد تشبیه کرد. با کشیدن کادرهایی (bounding boxes) دور این اشیا، میتوانیم بگوییم هر شیء کجای تصویر قرار دارد.
چرا تشخیص اشیا مهم است؟
- خودروهای خودران: شناسایی عابران پیاده، علائم ترافیکی و سایر خودروها در زمان واقعی.
- نظارت: تشخیص و ردیابی فعالیتهای مشکوک در جریانهای ویدئویی.
- مراقبتهای بهداشتی: شناسایی تومورها و ناهنجاریها در اسکنهای پزشکی.
Vision Transformers چیست؟
Vision Transformers (ViTs) که ابتدا توسط محققان گوگل معرفی شدند، یک فناوری پیشرفته هستند که از معماری Transformer استفاده میکنند. این معماری در ابتدا برای پردازش زبان طبیعی (NLP) طراحی شده بود، اما حالا برای درک و پردازش تصاویر به کار میرود. تصور کنید یک تصویر را به تکههای کوچک (مثل پازل) تقسیم کنیم و سپس با الگوریتمهای هوشمند بفهمیم این تکهها چه چیزی را نشان میدهند و چگونه به هم مرتبطاند.
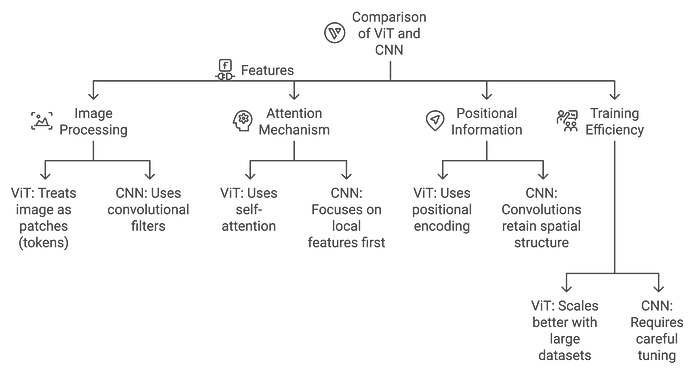
تفاوت ViTs با CNNها
- CNNها: در شناسایی الگوهای محلی (لبهها، بافتها) از طریق لایههای کانولوشنی کارآمد هستند.
- ViTs: از ابتدا الگوهای جهانی را ثبت میکنند و برای وظایفی که نیاز به درک کل زمینه تصویر دارند، مناسبترند.
توضیح معماری Transformer
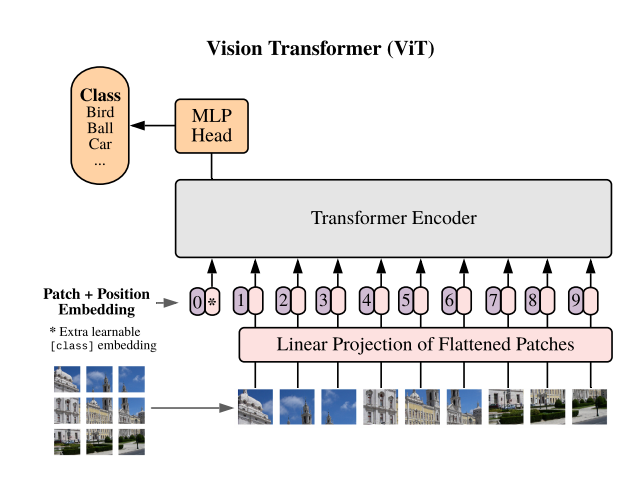
معماری Transformer که ابتدا برای وظایف مبتنی بر دنباله در NLP مثل ترجمه ماشینی طراحی شده بود، در ViTs برای دادههای بصری تطبیق داده شده است. در ادامه، توضیحی از نحوه کار آن ارائه میشود:
اجزای کلیدی معماری Transformer:
- Patch Embedding: تصویر به تکههای کوچک (مثلاً 16×16 پیکسل) تقسیم میشود و هر تکه به یک بردار خطی تبدیل میشود. این تکهها مشابه کلمات در وظایف NLP در نظر گرفته میشوند.
- Positional Encoding: چون Transformerها بهطور ذاتی اطلاعات مکانی را درک نمیکنند، کدگذاریهای موقعیتی اضافه میشوند تا موقعیت نسبی هر تکه حفظ شود.
- Self-Attention: این مکانیزم به مدل اجازه میدهد همزمان روی بخشهای مختلف تصویر (یا تکهها) تمرکز کند. هر تکه یاد میگیرد که روابطش با تکههای دیگر را وزندهی کند و این منجر به درک جهانی از تصویر میشود.
- Classification: خروجی تجمیعشده از طریق یک سر طبقهبندی (classification head) پردازش میشود و مدل پیشبینی میکند چه اشیایی در تصویر حضور دارند.
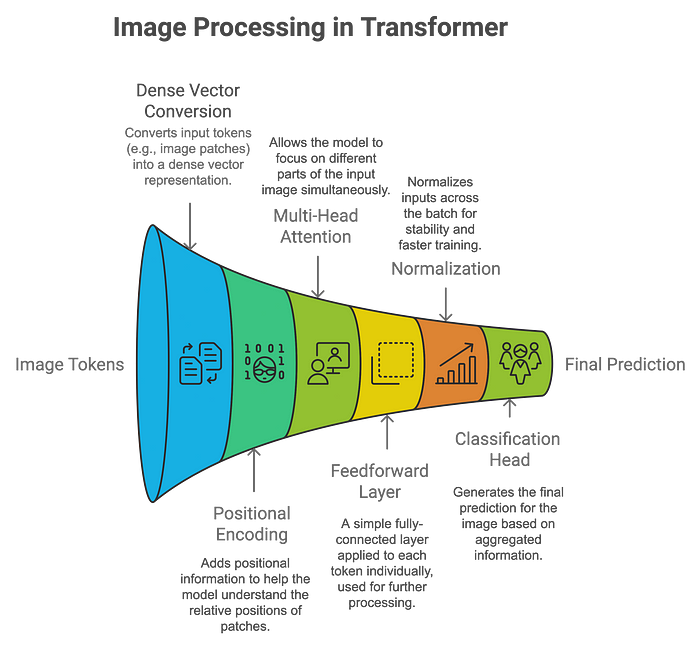
مزایای ViTs نسبت به CNNها:
- توانایی بهتر در ثبت زمینه جهانی: ViTs میتوانند وابستگیهای بلندمدت را مدلسازی کنند و برای درک صحنههای پیچیده مناسبترند.
- انعطافپذیری با اندازههای مختلف ورودی: برخلاف CNNها که به ورودیهایی با اندازه ثابت نیاز دارند، ViTs میتوانند با اندازههای مختلف تصویر سازگار شوند.
در اینجا یک نمودار وجود دارد که معماری Transformer در ViTs را با CNNها مقایسه میکند:
آمادهسازی پروژه
ما یک پروژه ساده تشخیص اشیا را با استفاده از PyTorch و یک Vision Transformer از پیش آموزشدیده راهاندازی میکنیم. ابتدا مطمئن شوید که کتابخانههای لازم را نصب کردهاید:
pip install torch torchvision matplotlib pillow ipywidgets
این کتابخانهها به این منظور کمک میکنند:
- PyTorch: بارگذاری و تعامل با مدل از پیش آموزشدیده.
- torchvision: پیشپردازش تصویر و اعمال تبدیلها.
- matplotlib: نمایش تصاویر و نتایج.
- pillow: مدیریت تصاویر.
- ipywidgets: ایجاد یک رابط کاربری تعاملی برای بارگذاری و پردازش تصاویر.
تشخیص اشیا با ViT به صورت گامبهگام
گام 1: بارگذاری و نمایش یک تصویر
ما با بارگذاری یک تصویر از وب و نمایش آن با استفاده از matplotlib شروع میکنیم.
import torch
from torchvision import transforms
from PIL import Image
import requests
from io import BytesIO
import matplotlib.pyplot as plt
# بارگذاری یک تصویر از یک URL
image_url = “https://upload.wikimedia.org/wikipedia/commons/2/26/YellowLabradorLooking_new.jpg”
# استفاده از یک user agent برای جلوگیری از مسدود شدن توسط وبسایت
headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36”
}
response = requests.get(image_url, headers=headers)
# بررسی موفقیتآمیز بودن درخواست
if response.status_code == 200:
image = Image.open(BytesIO(response.content))
# نمایش تصویر
plt.imshow(image)
plt.axis(‘off’)
plt.title(‘تصویر اصلی’)
plt.show()

گام 2: پیشپردازش تصویر
ViTs انتظار دارند تصویر قبل از ورود به مدل نرمالسازی شود.
from torchvision import transforms
preprocess = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
گام 3: بارگذاری مدل Vision Transformer از پیش آموزشدیده
اکنون یک مدل Vision Transformer از پیش آموزشدیده را از torchvision در PyTorch بارگذاری میکنیم.
from torchvision.models import vit_b_16
# گام 3: بارگذاری یک مدل Vision Transformer از پیش آموزشدیده
model = vit_b_16(pretrained=True)
model.eval() # تنظیم مدل در حالت ارزیابی (بدون آموزش در اینجا)
# عبور رو به جلو از مدل
with torch.no_grad(): # بدون نیاز به گرادیان، چون فقط استنتاج انجام میدهیم
output = model(input_batch)
# خروجی: این یک نتیجه طبقهبندی خواهد بود (مثلاً کلاسهای ImageNet)
گام 4: تفسیر خروجی
بیایید برچسب پیشبینیشده را از مجموعه داده ImageNet دریافت کنیم.
# گام 4: تفسیر خروجی
from torchvision import models
# بارگذاری برچسبهای ImageNet برای تفسیر
imagenet_labels = requests.get(“https://raw.githubusercontent.com/anishathalye/imagenet-simple-labels/master/imagenet-simple-labels.json”).json()
# دریافت شاخص بالاترین امتیاز
_, predicted_class = torch.max(output, 1)
# نمایش برچسب پیشبینیشده
predicted_label = imagenet_labels[predicted_class.item()]
print(f”برچسب پیشبینیشده: {predicted_label}”)
# نمایش نتیجه
plt.imshow(image)
plt.axis(‘off’)
plt.title(f”پیشبینیشده: {predicted_label}”)
plt.show()
برچسب پیشبینیشده: Labrador Retriever
ساخت یک طبقهبندیکننده تصویر تعاملی
ما میتوانیم این پروژه را کاربرپسندتر کنیم و یک ابزار تعاملی بسازیم که کاربران بتوانند تصاویر را بارگذاری کنند یا تصاویر نمونه را برای طبقهبندی انتخاب کنند. برای تعاملیتر شدن پروژه، از ipywidgets استفاده میکنیم تا یک رابط کاربری ایجاد کنیم که کاربران بتوانند تصاویر خود را بارگذاری کنند یا تصاویر نمونه را برای تشخیص اشیا انتخاب کنند.
import ipywidgets as widgets
from IPython.display import display, HTML, clear_output
from PIL import Image
import torch
import matplotlib.pyplot as plt
from io import BytesIO
import requests
from torchvision import transforms
# پیشپردازش تصویر
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# ایجاد سرصفحه با عنوان درخشان
header = HTML(“””
<div style=’text-align:center; margin-bottom:20px;’>
<h1 style=’font-family: Arial, sans-serif; color: #ffe814; font-size: 40px; text-shadow: 0 0 8px #39FF14;’>
Vision Transformer Object Detection
</h1>
<p style=’font-family: Arial, sans-serif; color: #ff14b5; font-size:20px’>یک تصویر بارگذاری کنید یا یک تصویر نمونه از کارتهای زیر انتخاب کنید</p>
</div>
“””)
# پاورقی با امضا
footer = HTML(“””
<div style=’text-align:center; margin-top:20px;’>
<p style=’font-family: Arial, sans-serif; color: #f3f5f2; font-size:25px’>قدرت گرفته از Vision Transformers | PyTorch | ipywidgets و ساختهشده توسط نوآوران هوش مصنوعی</p>
</div>
“””)
# بزرگتر کردن و مرکزی کردن دکمه بارگذاری
upload_widget = widgets.FileUpload(accept=’image/*’, multiple=False)
upload_widget.layout = widgets.Layout(width=’100%’, height=’50px’)
upload_widget.style.button_color = ‘#007ACC’
upload_widget.style.button_style = ‘success’
# تصاویر نمونه (به صورت کارت)
sample_images = [
(“سگ”, “https://upload.wikimedia.org/wikipedia/commons/2/26/YellowLabradorLooking_new.jpg”),
(“گربه”, “https://upload.wikimedia.org/wikipedia/commons/b/b6/Felis_catus-cat_on_snow.jpg”),
(“خودرو”, “https://upload.wikimedia.org/wikipedia/commons/f/fc/Porsche_911_Carrera_S_%287522427256%29.jpg”),
(“پرنده”, “https://upload.wikimedia.org/wikipedia/commons/3/32/House_sparrow04.jpg”),
(“لپتاپ”, “https://upload.wikimedia.org/wikipedia/commons/c/c9/MSI_Gaming_Laptop_on_wood_floor.jpg”)
]
# تابع برای نمایش و پردازش تصویر
def process_image(image):
# پاک کردن خروجیها و پیشبینیهای قبلی
clear_output(wait=True)
# نمایش مجدد سرصفحه، دکمه بارگذاری و تصاویر نمونه پس از پاکسازی
display(header)
display(upload_widget)
display(sample_buttons_box)
if image.mode == ‘RGBA’:
image = image.convert(‘RGB’)
# نمایش تصویر بارگذاریشده در مرکز
plt.imshow(image)
plt.axis(‘off’)
plt.title(‘تصویر بارگذاریشده’)
plt.show()
# پیشپردازش و پیشبینی
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
output = model(input_batch)
_, predicted_class = torch.max(output, 1)
predicted_label = imagenet_labels[predicted_class.item()]
# نمایش پیشبینی با فاصله و سبک
display(HTML(f”””
<div style=’text-align:center; margin-top:20px; font-size:30px; font-weight:bold; color:#39FF14; text-shadow: 0 0 8px #39FF14;’>
پیشبینیشده: {predicted_label}
</div>
“””))
# نمایش پاورقی پس از پیشبینی
display(footer)
# تابع فعالشده توسط بارگذاری فایل
def on_image_upload(change):
uploaded_image = Image.open(BytesIO(upload_widget.value[list(upload_widget.value.keys())[0]][‘content’]))
process_image(uploaded_image)
# تابع برای مدیریت انتخاب تصویر نمونه
def on_sample_image_select(image_url):
# تعریف هدرهای سفارشی با User-Agent معتبر
headers = {
‘User-Agent’: ‘MyBot/1.0 (your-email@example.com)’ # جایگزین با نام ربات و ایمیل تماس شما
}
response = requests.get(image_url, stream=True, headers=headers) # اضافه کردن هدرها
response.raise_for_status()
img = Image.open(response.raw)
process_image(img)
# افزودن دکمه برای هر تصویر نمونه به رابط کاربری (به صورت کارت)
sample_image_buttons = [widgets.Button(description=label, layout=widgets.Layout(width=’150px’, height=’150px’)) for label, _ in sample_images]
# اتصال هر دکمه به تصویر مربوطه
for button, (_, url) in zip(sample_image_buttons, sample_images):
button.on_click(lambda b, url=url: on_sample_image_select(url))
# نمایش دکمهها به صورت افقی
sample_buttons_box = widgets.HBox(sample_image_buttons, layout=widgets.Layout(justify_content=’center’))
# اتصال ابزار بارگذاری به تابع
upload_widget.observe(on_image_upload, names=’value’)
# نمایش رابط کاربری کامل
display(header)
display(upload_widget) # نمایش ابزار بارگذاری فایل
display(sample_buttons_box) # نمایش کارتهای تصاویر نمونه

پرسشهای متداول
- آیا Vision Transformers قابل تنظیم دقیق (fine-tuning) هستند؟ بله، Vision Transformers از پیش آموزشدیده میتوانند روی مجموعه دادههای سفارشی برای وظایفی مثل تشخیص اشیا و تقسیمبندی تنظیم دقیق شوند.
- آیا ViTs از نظر محاسباتی گران هستند؟ ViTs به دلیل مکانیزم Self-Attention، هزینه محاسباتی بالاتری نسبت به CNNها دارند، بهویژه برای مجموعه دادههای کوچک.
- چه مجموعه دادههایی برای آموزش ViTs مناسباند؟ مجموعه دادههای بزرگ مثل ImageNet برای آموزش ViTs ایدهآل هستند، زیرا مزیت مقیاسپذیری آنها نسبت به CNNها را نشان میدهند.
گامهای بعدی پردازش تصاویر
شما اکنون اصول اولیه Vision Transformers را آموختهاید و تشخیص اشیا را با استفاده از PyTorch پیادهسازی کردهاید. در ادامه، میتوانید با تنظیم دقیق ViTs روی مجموعه دادههای سفارشی یا کاوش در مدلهای مبتنی بر Transformer دیگر مثل DETR (Detection Transformer) آزمایش کنید.
نتیجهگیری
Vision Transformers (ViTs) یک جهش بزرگ در حوزه Computer Vision هستند و جایگزینی تازه برای روشهای مبتنی بر CNN ارائه میدهند. با بهرهگیری از توانایی معماری Transformer در ثبت زمینه جهانی از ابتدا، ViTs عملکرد چشمگیری را بهویژه روی مجموعه دادههای بزرگ نشان دادهاند.
در این مقاله، ما اصول اولیه Object Detection، نحوه کار Vision Transformers و پیادهسازی یک پروژه تشخیص اشیا را به صورت گامبهگام بررسی کردیم. با ادامه تکامل دنیای Computer Vision، کاوش در Transformerها و انواع آنها مثل DETR امکانات پیشرفتهتری را باز خواهد کرد.
چه مبتدی باشید و چه حرفهای، تنظیم دقیق ViTs برای مجموعه دادههای سفارشی یا ترکیب آنها با مدلهای دیگر میتواند نتایج شما را بهبود ببخشد. آینده مدلهای بصری هیجانانگیز است و Vision Transformers قطعاً در خط مقدم این تکامل قرار دارند! موفق باشید در مدلسازی!
