
آشنایی با الگوریتمهای تشخیص اشیا
Computer vision یک حوزه بینرشتهای است که در سالهای اخیر، بهخصوص از زمان ظهور CNNها، توجه زیادی به خود جلب کرده است. خودراهای خودران بهعنوان یکی از مهمترین کاربردهای این حوزه مطرح شدند و در این بین، تشخیص اشیا نیز نقش کلیدی دارد. تشخیص اشیا در کارهایی مثل تخمین حالت (pose estimation)، شناسایی خودراها، نظارت و امنیت به کار میراد. تفاوت اصلی الگوریتمهای تشخیص اشیا با الگوریتمهای طبقهبندی این است که در تشخیص اشیا، ما یک bounding box دور شیء موردنظر میکشیم تا موقعیتش را در تصویر مشخص کنیم. نکته جالب این است که در یک تصویر ممکن است چند bounding box داشته باشیم که هر کدام یک شیء متفاوت را نشان دهند که تعدادشان از قبل مشخص نیست.


چالش اصلی الگوریتم های تشخیص اشیا
اگه بخواهیم این مسئله را با یک شبکه کانولوشنی معمولی و یک لایک fully connected حل کنیم، به مشکل بر میخوریم. چون طول لایک خراجی متغیر است و به تعداد اشیای موجود در تصویر بستگی دارد. یک راه ساده و اولیه این است که مناطق مختلف تصویر را جدا کنیم و با CNN بررسی کنیم که آیا شیء موردنظر در آن منطقه هست یا نه. اما مشکل اینجاست که ممکن است؛ اشیا در جاهای مختلف تصویر با نسبتهای ابعادی (aspect ratios) متفاوت باشند. برای همین، باید مناطق زیادی را بررسی کنیم که این مساله از نظر محاسباتی خیلی سنگین میشود. به همین خاطر، الگوریتمهایی مثل R-CNN و YOLO طراحی شدند تا این اشیا را سریعتر و بهتر پیدا کنند.
الگوریتم تشخیص اشیا R-CNN
برای حل مشکل بررسی تعداد زیاد مناطق، Ross Girshick و همکارانش راشی پیشنهادی مطرح کردند که در آن روش از selective search استفاده میشه تا فقط 2000 منطقه از تصویر استخراج شود. به این مناطق region proposals میگویند. حالا به جای اینکه کل تصویر را منطقهبهمنطقه بررسی کنیم، فقط این 2000 منطقه را پردازش میکنیم. این region proposals با الگوریتم selective search تولید میشود که مراحل آن به این شکل است:
- اول یک تقسیمبندی اولیه انجام میشود و مناطق کاندید زیادی تولید میشود.
- بعد با یک الگوریتم greedy، مناطق شبیه به هم بهصورت بازگشتی ترکیب شده و بزرگتر میشوند.
- در نهایت، از این مناطق برای تولید region proposals نهایی استفاده میشود.
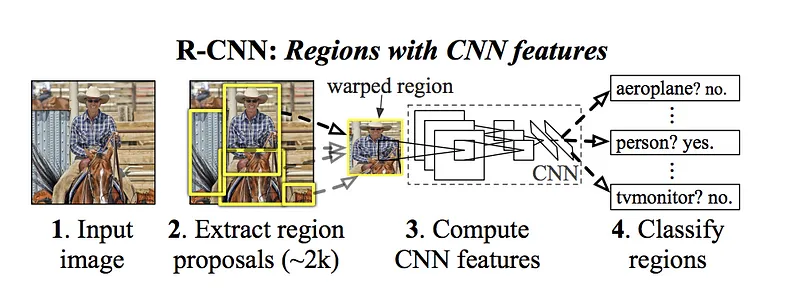
این 2000 منطقه کاندید به شکل مربع و به یک شبکه کانولوشنی (CNN) داده میشوند که یک بردار ویژگی 4096بعدی تولید میکند. اینجا CNN نقش یک feature extractor را دارد. این ویژگیهای استخراجشده به یک SVM داده میشود تا مشخص کند در آن منطقه شیء هست یا نه. علاوه بر این، الگوریتم چهار مقدار offset هم پیشبینی میکند که تا حد بسیار زیادی به دقیقتر شدن bounding box کمک میکند. مثلاً ممکن است یک region proposal نشان دهد که یک فرد در تصویر هست، ولی صورتش نصفه باشد؛ این offsetها bounding box را تنظیم میکنند.
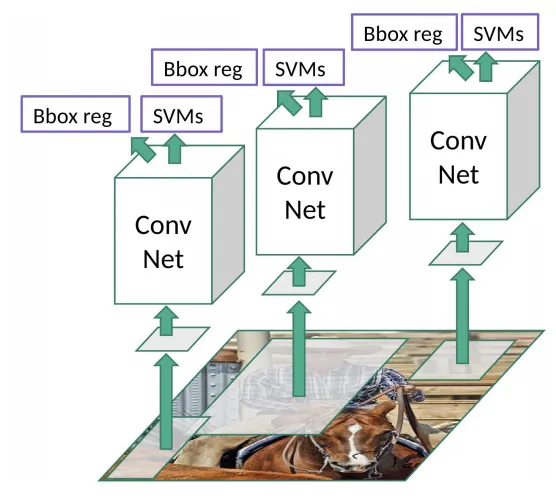
مشکلات R-CNN
- آموزش شبکه هنوز زمان زیادی میبرد، زیرا باید برای هر تصویر 2000 منطقه بررسی شود.
- این روش به صورت real-time پیادهسازی نمیشود، چون بررسی هر تصویر تستی حدود 47 ثانیه طول میکشد.
- الگوریتم selective search ثابت و بدون یادگیری است، در نتیجه امکان تولید تصاویر بیکیفیت در region proposals بالاست.
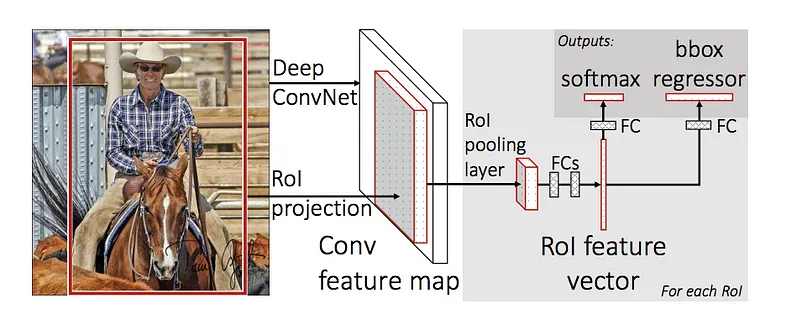
الگوریتم تشخیص اشیا Fast R-CNN
همان نویسنده R-CNN، یعنی Ross Girshick، برای رفع بعضی از مشکلات قبلی، الگوریتم Fast R-CNN را پیشنهاد داد. روش کار راش شبیه R-CNN است، ولی یک تفاوت بزرگ دارد: در این مورد، به جای اینکه region proposals را مستقیم به CNN بدهیم، اول کل تصویر را به CNN میدهیم تا یک convolutional feature map تولید شود. بعد از رای این نقشه ویژگی، region proposals شناسایی و به شکل مربع درمیآیند. با استفاده از یک لایک RoI pooling، این مناطق به اندازه ثابت تغییر شکل میدهند تا امکان اتصال به یک لایک fully connected ممکن شود. در نهایت، از یک softmax layer برای پیشبینی کلاس منطقه و مقدار offsetهای bounding box استفاده میشود.
چرا Fast R-CNN سریعتر است؟
در این راش، عملیات convolution فقط یک بار برای کل تصویر انجام میشود و در نتیجه یک feature map تولید میشود. این مساله به این معنی است که دیگر لازم نیست 2000 منطقه را جداگانه به CNN داده شود،به همین دلیل سرعت این روش بیشتر از R-CNN است.
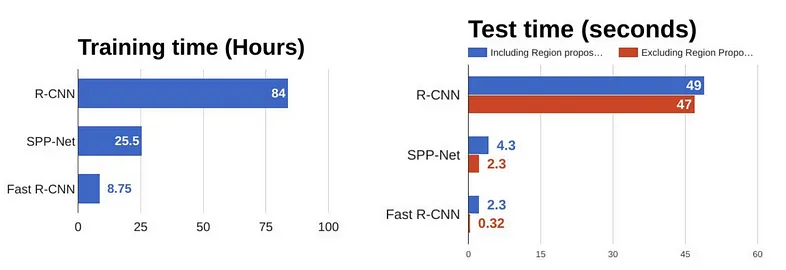
از مقایسهها دیده میشود که Fast R-CNN در آموزش و تست بسیار سریعتر از R-CNN عمل میکند. اما اگردر زمان تست، region proposals را هم حساب کنیم، سرعتش کمتر میشود. پسregion proposals هنوز یک گلوگاه توی این الگوریتم هست که بر روی عملکرد آن تأثیر میگذارد.
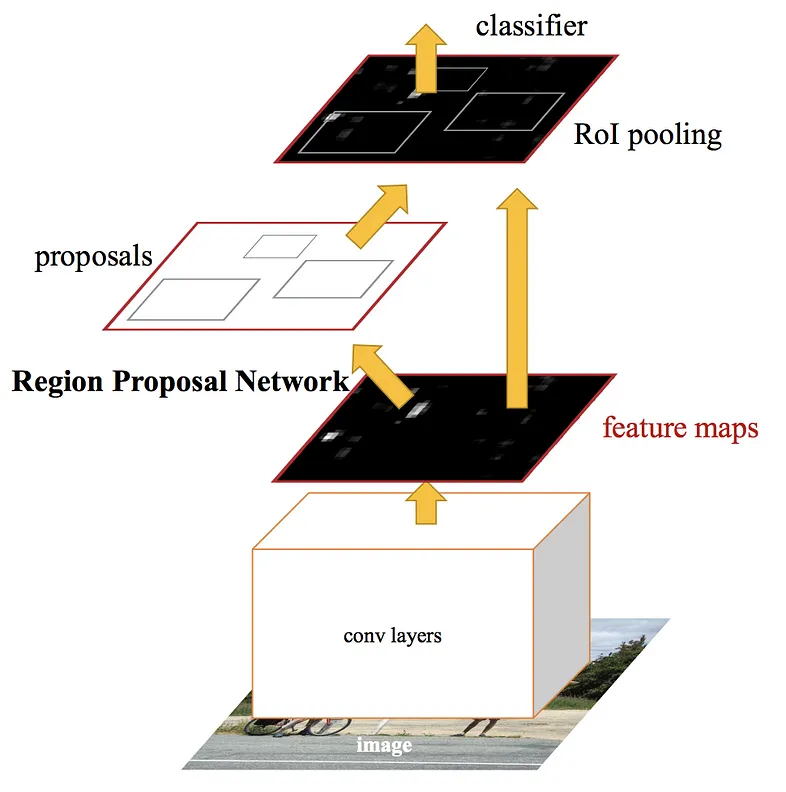
الگوریتم تشخیص اشیا Faster R-CNN
هر دو الگوریتم قبلی (R-CNN و Fast R-CNN) از selective search برای پیدا کردن region proposals استفاده میکردند. اما selective search یک فرایند کند و زمانبر است که بر روی عملکرد شبکه تأثیر منفی میگذارد. به همین علت، Shaoqing Ren و همکارانش الگوریتمی پیشنهاد دادند که selective search را حذف میکند و به شبکه اجازه میدهد خودش region proposals را یاد بگیرد.
مثل Fast R-CNN، در این راش هم تصویر به یک شبکه کانولوشنی داده میشود و در نتیجه یک convolutional feature map تولید میشود. اما به جای استفاده از selective search روی این نقشه ویژگی، یک شبکه جداگانه region proposals را پیشبینی میکند. این region proposals پیشبینیشده با یک لایک RoI pooling تغییر شکل داده میشود تا به اندازه ثابت برسد. در نهایت، از این روش برای طبقهبندی تصویر در منطقه پیشنهادی و پیشبینی مقدار offsetهای bounding box استفاده میشود.
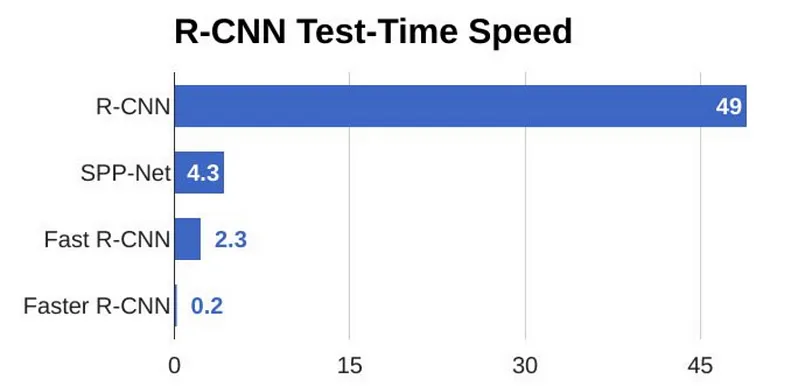
از نمودارها میشود فهمید که Faster R-CNN خیلی سریعتر از نسخههای قبلی است. به همین علت، حتی میتوان از آن در real-time object detection نیز استفاده کرد.
الگوریتم تشخیص اشیا YOLO — You Only Look Once
الگوریتمهای قبلی تشخیص اشیا همگی از مناطق (regions) برای پیدا کردن اشیا در تصویر استفاده میکردند. یعنی شبکه کل تصویر را نگاه نمیکرد، فقط قسمتهایی که احتمال وجود شیء در آنها بیشتر بود. اما YOLO یا You Only Look Once یک الگوریتم تشخیص اشیاست که با الگوریتمهای مبتنی بر منطقه بسیار متفاوت است. در YOLO، یک شبکه کانولوشنی واحد هم bounding boxها را و هم احتمال کلاس این boxها را پیشبینی میکند.
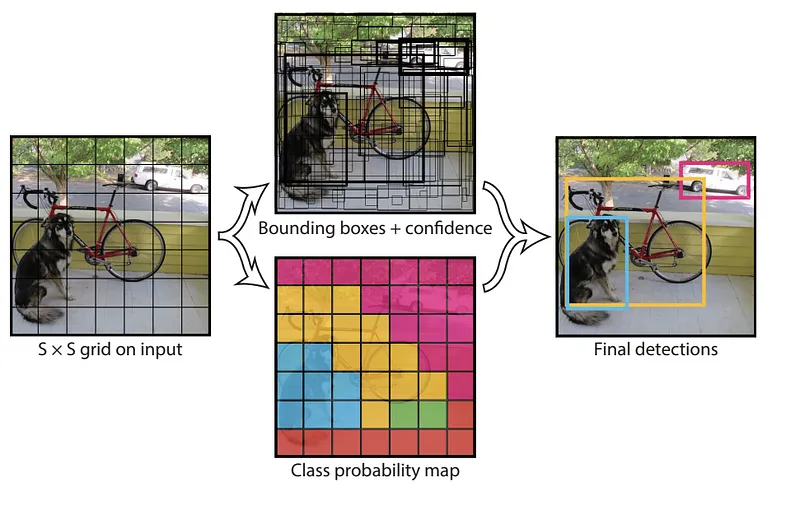
نحوه کار YOLO به این شکل است که تصویر را به یک گرید S×S تقسیم میکنیم. در هر سلول گرید، m تا bounding box در نظر میگیریم. شبکه برای هر bounding box یک احتمال کلاس و مقدار offset پیشبینی میکند. bounding boxهایی که احتمال کلاسشان از یک آستانه مشخص بیشتر باشد، انتخاب شده و برای پیدا کردن موقعیت شیء در تصویر استفاده میشوند.
YOLO بسیار سریعتر از بقیه الگوریتمهای تشخیص اشیا اسست و میتواند 45 فریم در ثانیه را پردازش کند. ولی همچنان یک محدودیت مهم دارد: این الگوریتم برای تشخیص اشیای کوچک تصویر مشکل دارد. مثلاً ممکن است نتواند یک گله پرنده را به درستی تشخیص دهد. این مشکل به خاطر محدودیتهای فضایی (spatial constraints) الگوریتم است.
نتیجهگیری
کنفرانسهای Computer vision هر سال ایدههای جدید و جذابی را معرفی میکنند و این ایده ها قدم به قدم ما را به سمت عملکردهای شگفتانگیز هوش مصنوعی پیش میبرند (اگه هنوز نرسیده باشیم!). و بهبودهای بسیاری حاصل شده است.
References
- https://arxiv.org/pdf/1311.2524.pdf
- https://arxiv.org/pdf/1504.08083.pdf
- https://arxiv.org/pdf/1506.01497.pdf
- https://arxiv.org/pdf/1506.02640v5.pdf
- http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
